


1、场景:当企业微信以及微信发起手机号查询成功之后会得到手机号对应微信的头像、昵称、城市、phash值等信息。此外我们有一个表保存基础服务收集到的用户头像昵称以及微信信息等。
这个表的数据非常多,大概有7kw-8kw。
2、事故现场: 第一次首先根据nickname在库里查询数据,如果超过限制就不发起匹配。
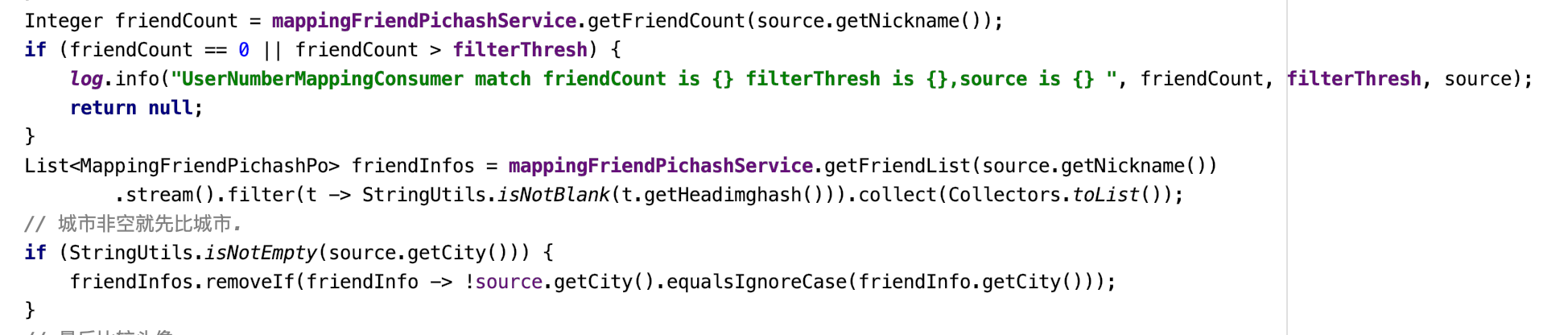
3、修改原有日志级别之后之前不会报慢sql的问题频繁出现了。

4、加上city查询条件并加联合索引、以及分页查询。
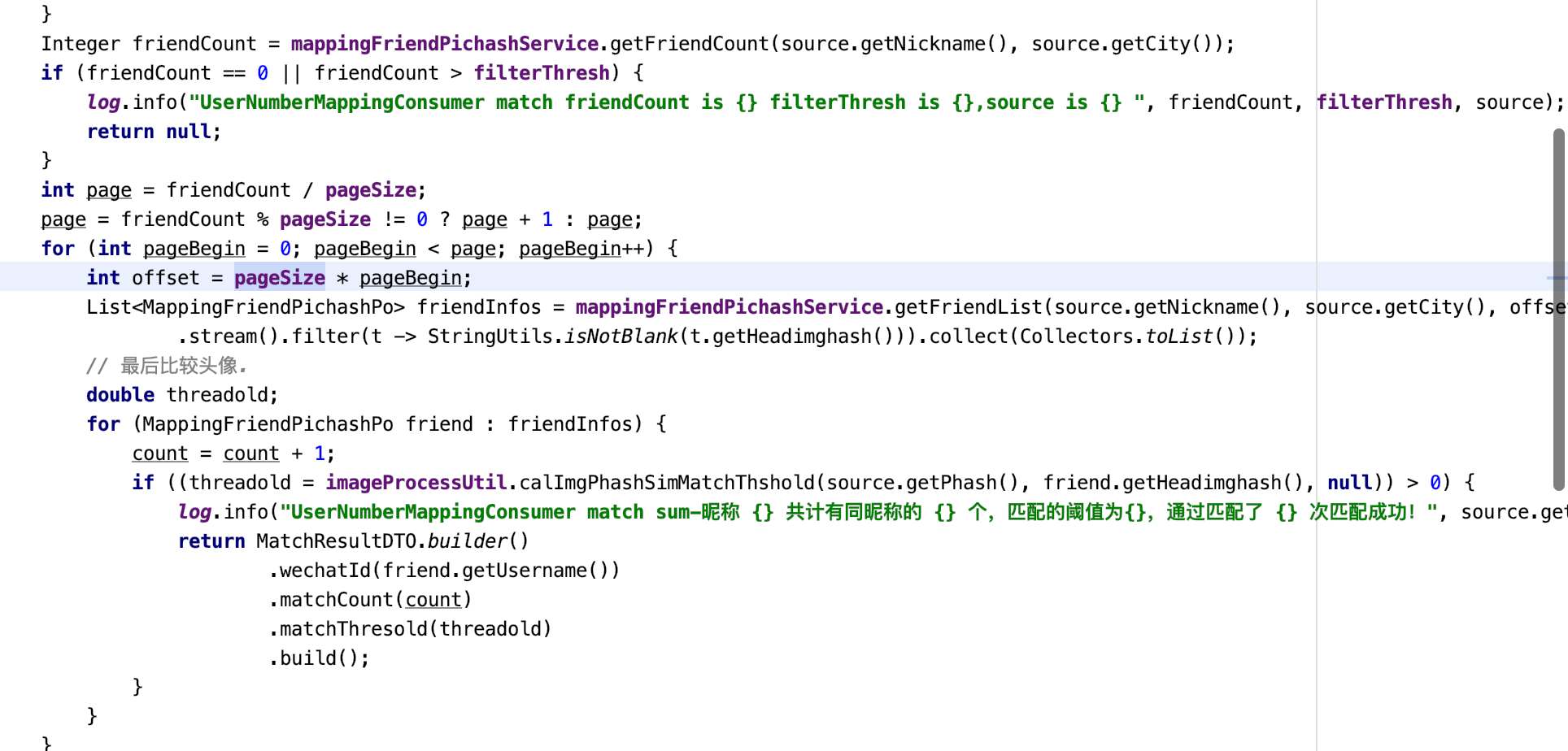
5、分页之后仍然出现slow sql问题,与leader以及同事沟通之后

1、limit语句的查询时间与起始记录的位置成正比。
2、mysql的limit语句是很方便,但是对记录很多的表并不适合直接使用。
2.1 利用表的覆盖索引来加速分页查询
我们都知道,利用了索引查询的语句中如果只包含了那个索引列(覆盖索引),那么这种情况会查询很快。
因为利用索引查找有优化算法,且数据就在查询索引上面,不用再去找相关的数据地址了,这样节省了很多时间。
另外Mysql中也有相关的索引缓存,在并发高的时候利用缓存就效果更好了。
如果查询所有数据有两种方法:
1)、利用
id>=的形式:
2)、利用临时表join的方法
这里我根据我的使用场景采用第二种

1、此表数据过大、而且考虑到后续可能还会继续增大、可能会采取分表策略。
评论区