


一、安装中文分词器插件
国内最常用的:
- elasticsearch-analysis-ik
- elasticsearch-analysis-pinyin
- elasticsearch-analysis-stconvert
1、下载插件压缩包
wget https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v7.3.0/elasticsearch-analysis-ik-7.3.0.zip
2、将压缩包拷贝到es容器内部
- 1)进入es容器内部,并创建插件目录。
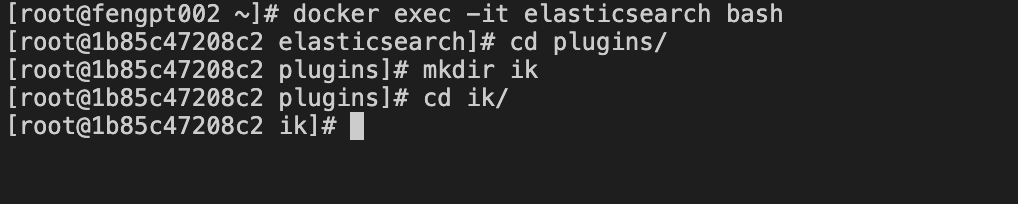
- 2)使用exit命令退回宿主机,将压缩包拷贝到es容器刚才创建的目录下
docker cp /home/elasticsearch-analysis-ik-7.3.0.zip elasticsearch:/usr/share/elasticsearch/plugins/ik
- 3)再次进入es容器内部,使用unzip命令将压缩包解压。
yum install unzip
unzip elasticsearch-analysis-ik-7.3.0.zip
rm -rf elasticsearch-analysis-ik-7.3.0.zip
- 4)重启es。
二、简单使用
测试分词
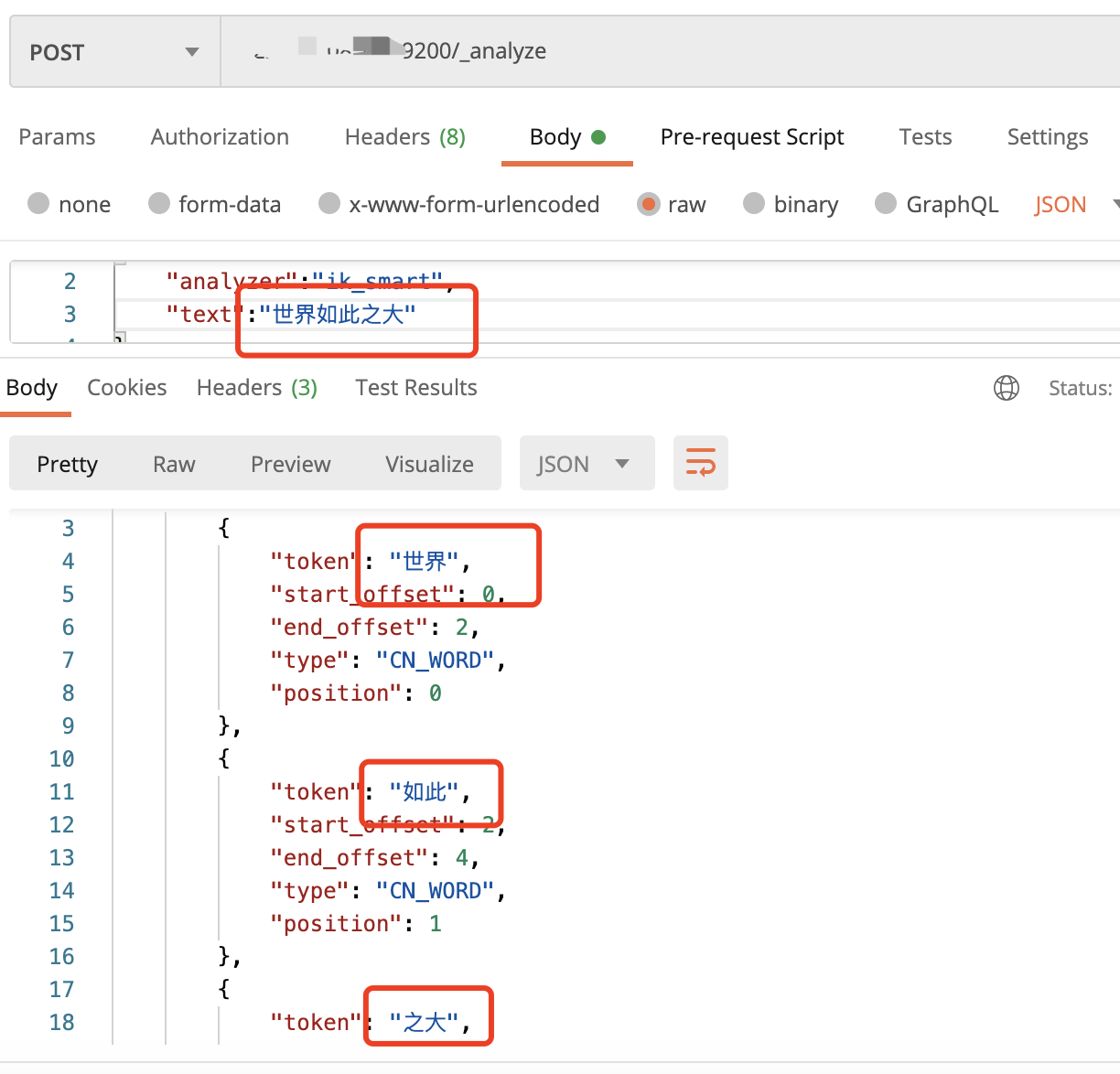
- ik_smart:

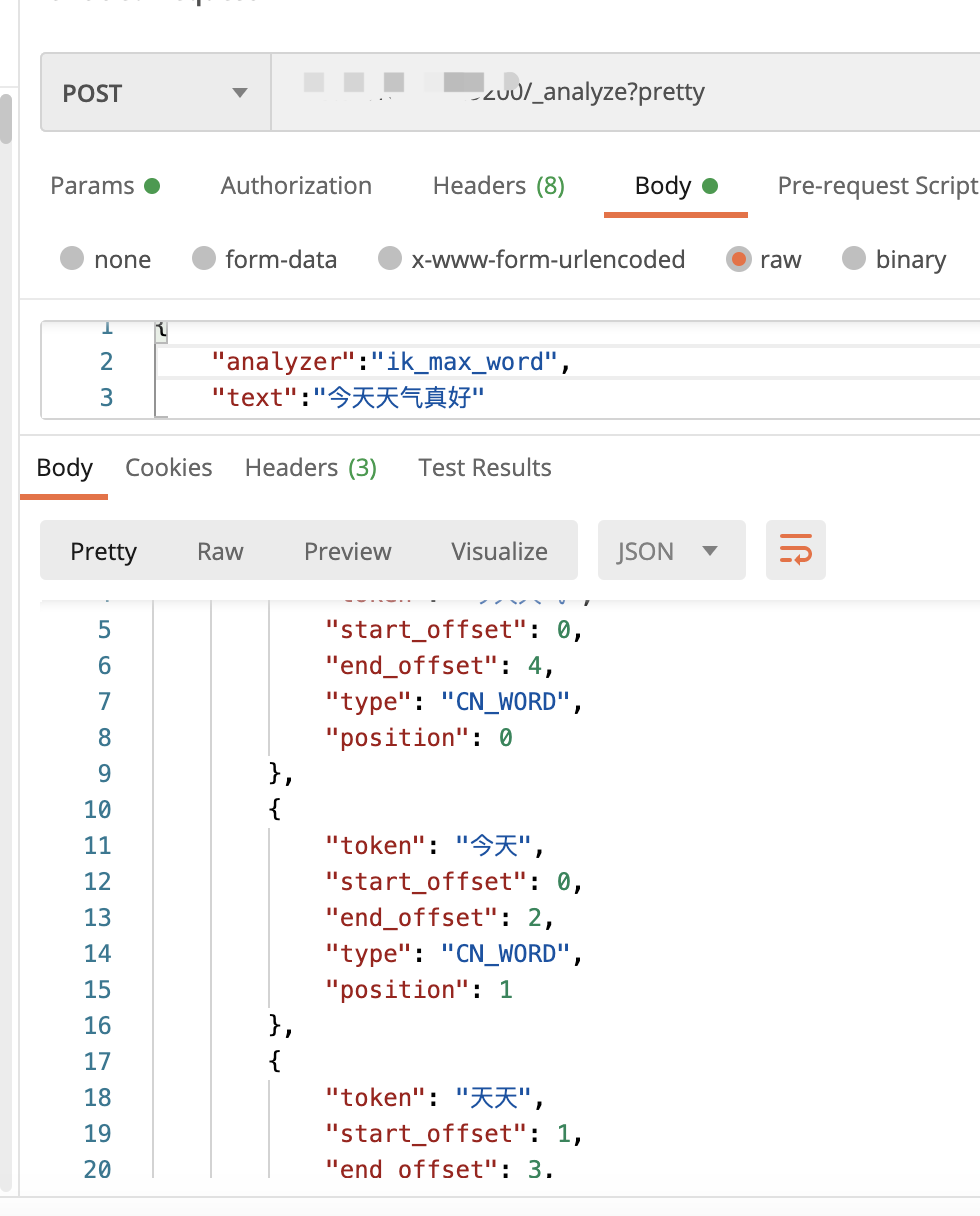
- ik_max_word:
{
"tokens": [
{
"token": "今天天气",
"start_offset": 0,
"end_offset": 4,
"type": "CN_WORD",
"position": 0
},
{
"token": "今天",
"start_offset": 0,
"end_offset": 2,
"type": "CN_WORD",
"position": 1
},
{
"token": "天天",
"start_offset": 1,
"end_offset": 3,
"type": "CN_WORD",
"position": 2
},
{
"token": "天气",
"start_offset": 2,
"end_offset": 4,
"type": "CN_WORD",
"position": 3
},
{
"token": "真好",
"start_offset": 4,
"end_offset": 6,
"type": "CN_WORD",
"position": 4
}
]
}
ik_max_word: 会将文本做最细粒度的拆分,会穷尽各种可能的组合;
ik_smart: 会做最粗粒度的拆分。已被分出的词语将不会再次被其它词语占有。
评论区