


1、Kubernetes是什么
Kubernetes是一个轻便的和可扩展的开源平台,用于管理容器化应用和服务。通过Kubernetes能够进行应用的自动化部署和扩缩容。在Kubernetes中,会将组成应用的容器组合成一个逻辑单元以更易管理和发现。Kubernetes积累了作为Google生产环境运行工作负载15年的经验,并吸收了来自于社区的最佳想法和实践。Kubernetes经过这几年的快速发展,形成了一个大的生态环境,Google在2014年将Kubernetes作为开源项目。Kubernetes的关键特性包括:
- 自动化装箱:在不牺牲可用性的条件下,基于容器对资源的要求和约束自动部署容器。同时,为了提高利用率和节省更多资源,将关键和最佳工作量结合在一起。
- 自愈能力:当容器失败时,会对容器进行重启;当所部署的Node节点有问题时,会对容器进行重新部署和重新调度;当容器未通过监控检查时,会关闭此容器;直到容器正常运行时,才会对外提供服务。
- 水平扩容:通过简单的命令、用户界面或基于CPU的使用情况,能够对应用进行扩容和缩容。
- 服务发现和负载均衡:开发者不需要使用额外的服务发现机制,就能够基于Kubernetes进行服务发现和负载均衡。
- 自动发布和回滚:Kubernetes能够程序化的发布应用和相关的配置。如果发布有问题,Kubernetes将能够回归发生的变更。
- 保密和配置管理:在不需要重新构建镜像的情况下,可以部署和更新保密和应用配置。
- 存储编排:自动挂接存储系统,这些存储系统可以来自于本地、公共云提供商(例如:GCP和AWS)、网络存储(例如:NFS、iSCSI、Gluster、Ceph、Cinder和Floker等)。
2、Kubernetes基本知识
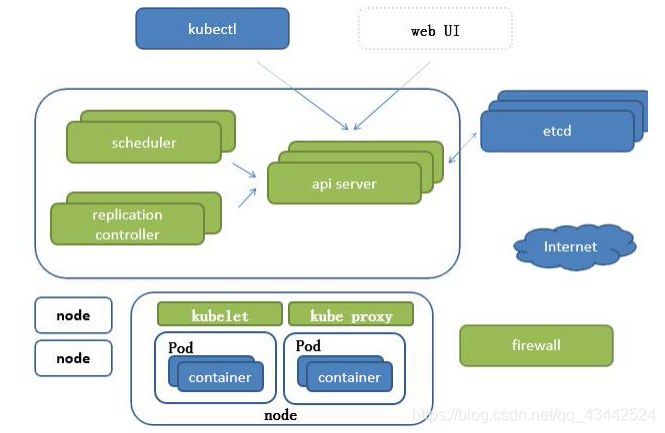
Kubernetes架构:

Pod:
容器给我们提供了强大的隔离功能,所以有必要把为Service提供服务的这组进程放入容器中进行隔离。为此,Kubernetes设计了Pod对象,将每个服务进程都包装到相应的Pod中,使其成为在Pod中运行的一个容器(Container)
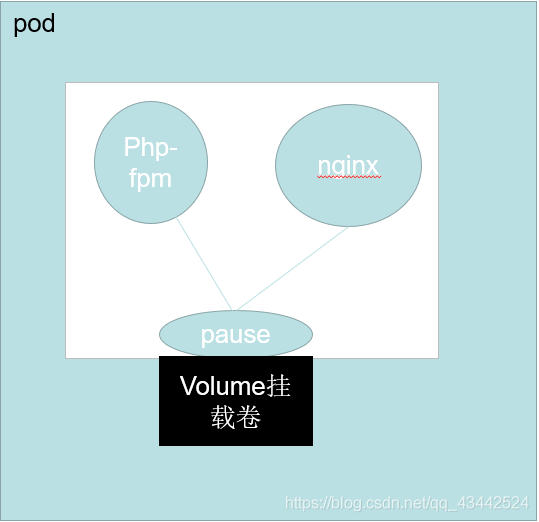
Pod运行在一个被称为节点(Node)的环境中,这个节点既可以是物理机,也可以是一个虚拟机,通常在一个节点上运行几百个Pod;其次,在每个Pod中都运行着一个特殊的被称为Pause的容器,其他容器则为业务容器,这些业务容器共享Pause容器的网络栈和Volume挂载卷,因此它们之间的通信和数据交换更为高效,在设计时我们可以充分利用这一特性将一组密切相关的服务进程放入同一个Pod中;
每当启动一个pod的时候,pause容器也会随之启动
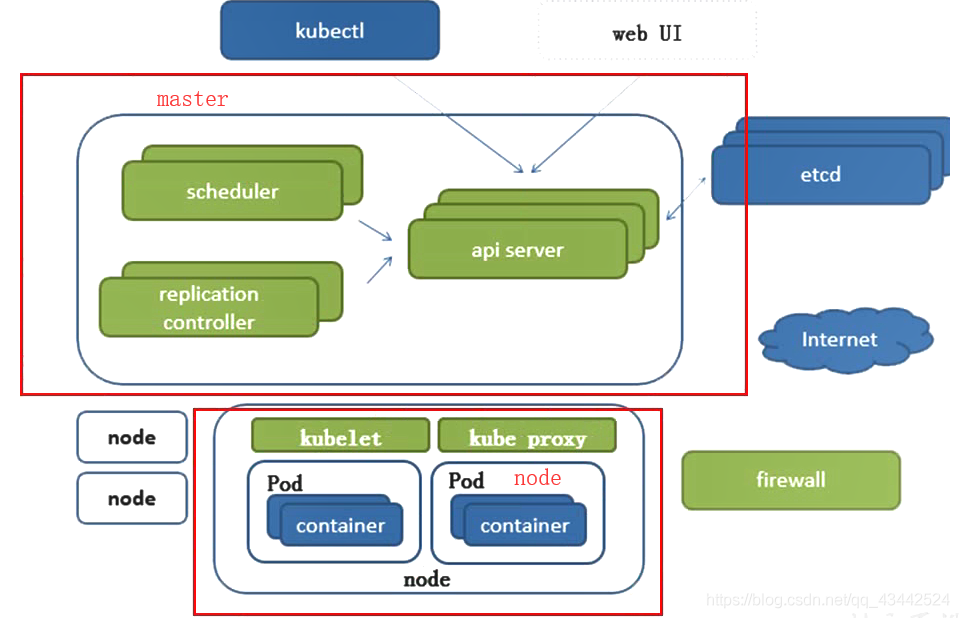
Kubernetes将集群中的机器划分为一个Master和一些Node。在Master上运行着集群管理相关的一组进程kube-apiserver、kube-controller-manager和kubescheduler,这些进程实现了整个集群的资源管理、Pod调度、弹性伸缩、安全控制、系统监控和纠错等管理功能,并且都是自动完成的。
Node作为集群中的工作节点,运行真正的应用程序,在Node上Kubernetes管理的最小运行单元是Pod。在Node上运行着Kubernetes的kubelet、kube-proxy服务进程,这些服务进程负责Pod的创建、启动、监控、重启、销毁,以及实现软件模式的负载均衡器。
Service:
在Kubernetes中,Service是分布式集群架构的核心,一个Service对象拥有如下关键特征。
拥有唯一指定的名称(比如mysql-server)。
拥有一个虚拟IP(Cluster IP、Service IP或VIP)和端口号。
能够提供某种远程服务能力。
被映射到提供这种服务能力的一组容器应用上。
Service的服务进程目前都基于Socket通信方式对外提供服务,比如Redis、Memcache、MySQL、Web Server,或者是实现了某个具体业务的特定TCP Server进程。
虽然一个Service通常由多个相关的服务进程提供服务,每个服务进程都有一个独立的Endpoint(IP+Port)访问点,但Kubernetes能够让我们通过Service(虚拟Cluster IP +Service Port)连接到指定的Service。有了Kubernetes内建的透明负载均衡和故障恢复机制,不管后端有多少服务进程,也不管某个服务进程是否由于发生故障而被重新部署到其他机器,都不会影响对服务的正常调用。更重要的是,这个Service本身一旦创建就不再变化,这意味着我们再也不用为Kubernetes集群中服务的IP地址变来变去的问题而头疼了。
Etce:
etcd的官方将它定位成一个可信赖的分布式键值存储服务,它能够为整个分布式集群存储一些关键数据,协助分布式集群的正常运转
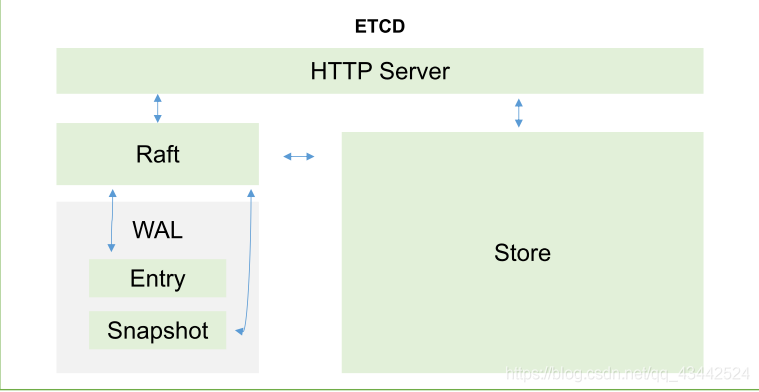
Raft: 读写信息的存储
WAL: 预写日志,并且定时对这些日志进行备份
Store: 实时把日志和数据持久化传入本地磁盘中
Replication Controller
Replication Controller(RC)是Kubernetes系统中的核心概念之一,简单来说,它其实定义了一个期望的场景,即声明某种Pod的副本数量在任意时刻都符合某个预期值,所以RC的定义包括如下几个部分:
- Pod期待的副本数量
- 用于筛选目标Pod的Label Selector
- 当Pod的副本数量小于预期数量时,用于创建新Pod的Pod模板(template)
在我们定义了一个RC并将其提交到Kubernetes集群中后,Master上的Controller Manager组件就得到通知,定期巡检系统中当前存活的目标Pod,并确保目标Pod实例的数量刚好等于此RC的期望值,如果有过多的Pod副本在运行,系统就会停掉一些Pod,否则系统会再自动创建一些Pod。
通过RC,Kubernetes实现了用户应用集群的高可用性,并且大大减少了系统管理员在传统IT环境中需要完成的许多手工运维工作(如主机监控脚本、应用监控脚本、故障恢复脚本等)。
在Kubernetes 1.2中,升级为另外一个新概念—Replica Set,官方解释其为“下一代的RC”。Replica Set与RC当前的唯一区别是,Replica Sets支持基于集合的Label selector(Set-based selector),而RC只支持基于等式的Label Selector(equality-based selector),这使得Replica Set的功能更强。
RS(Replica Set)的一些特性与作用:
- 在大多数情况下,我们通过定义一个RC实现Pod的创建及副本数量的自动控制。
- 在RC里包括完整的Pod定义模板。
- RC通过Label Selector机制实现对Pod副本的自动控制。
- 通过改变RC里的Pod副本数量,可以实现Pod的扩容或缩容。
- 通过改变RC里Pod模板中的镜像版本,可以实现Pod的滚动升级。
Deployment
Deployment是Kubernetes在1.2版本中引入的新概念,用于更好地解决Pod的编排问题。为此,Deployment在内部使用了Replica Set来实现目的,无论从Deployment的作用与目的、YAML定义,还是从它的具体命令行操作来看,我们都可以把它看作RC的一次升级,两者的相似度超过90%。
Deployment相对于RC的一个最大升级是我们可以随时知道当前Pod“部署”的进度。实际上由于一个Pod的创建、调度、绑定节点及在目标Node上启动对应的容器这一完整过程需要一定的时间,所以我们期待系统启动N个Pod副本的目标状态,实际上是一个连续变化的“部署过程”导致的最终状态。
Deployment的典型使用场景有以下几个:
- 创建一个Deployment对象来生成对应的Replica Set并完成Pod副本的创建。
- 检查Deployment的状态来看部署动作是否完成(Pod副本数量是否达到预期的值)。
- 更新Deployment以创建新的Pod(比如镜像升级)。
- 如果当前Deployment不稳定,则回滚到一个早先的Deployment版本。
- 暂停Deployment以便于一次性修改多个PodTemplateSpec的配置项,之后再恢复Deployment,进行新的发布。
- 扩展Deployment以应对高负载。
- 查看Deployment的状态,以此作为发布是否成功的指标。
- 清理不再需要的旧版本ReplicaSets。
HPA(HorizontalPodAutoScale)
Horizontal Pod Autoscaling 仅适用于Deployment 和ReplicaSet ,在V1 版本中仅支持根据Pod 的CPU 利用率扩所容,在v1alpha 版本中,支持根据内存和用户自定义的metric 扩缩容
HPA与之前的RC、Deployment一样,也属于一种Kubernetes资源对象。通过追踪分析指定RC控制的所有目标Pod的负载变化情况,来确定是否需要有针对性地调整目标Pod的副本数量,这是HPA的实现原理。
StatefulSet
StatefulSet是为了解决有状态服务的问题(对应Deployments 和ReplicaSets是为无状态服务而设计)
其应用场景包括:
- 稳定的持久化存储,即Pod 重新调度后还是能访问到相同的持久化数据,基于PVC 来实现
- 稳定的网络标志,即Pod 重新调度后其PodName和HostName不变,基于Headless Service (即没有Cluster IP 的Service )来实现
- 有序部署,有序扩展,即Pod 是有顺序的,在部署或者扩展的时候要依据定义的顺序依次依次进行(即从0 到N-1,在下一个Pod 运行之前所有之前的Pod 必须都是Running 和Ready 状态),基于init containers 来实现
- 有序收缩,有序删除(即从N-1 到0)
Pod、RC与Service的逻辑关系图:
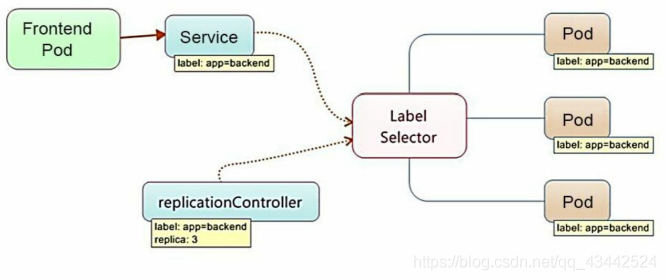
从图中可以看到,Kubernetes的Service定义了一个服务的访问入口地址,前端的应用(Pod)通过这个入口地址访问其背后的一组由Pod副本组成的集群实例,Service与其后端Pod副本集群之间则是通过Label Selector来实现无缝对接的。RC的作用实际上是保证Service的服务能力和服务质量始终符合预期标准。
Job Cron Job
Job 负责批处理任务,即仅执行一次的任务,它保证批处理任务的一个或多个Pod 成功结束
Cron Job管理基于时间的Job,即:在给定时间点只运行一次周期性地在给定时间点运行
Volume
Volume(存储卷)是Pod中能够被多个容器访问的共享目录。
Kubernetes的Volume概念、用途和目的与Docker的Volume比较类似,但两者不能等价。
首先,Kubernetes中的Volume被定义在Pod上,然后被一个Pod里的多个容器挂载到具体的文件目录下;其次,Kubernetes中的Volume与Pod的生命周期相同,但与容器的生命周期不相关,当容器终止或者重启时,Volume中的数据也不会丢失。最后,Kubernetes支持多种类型的Volume,例如GlusterFS、Ceph等先进的分布式文件系统。
Namespace
Namespace(命名空间)是Kubernetes系统中的另一个非常重要的概念,Namespace在很多情况下用于实现多租户的资源隔离。
Namespace通过将集群内部的资源对象“分配”到不同的Namespace中,形成逻辑上分组的不同项目、小组或用户组,便于不同的分组在共享使用整个集群的资源的同时还能被分别管理。
评论区