
spring boot Sharding-jdbc 分表分库
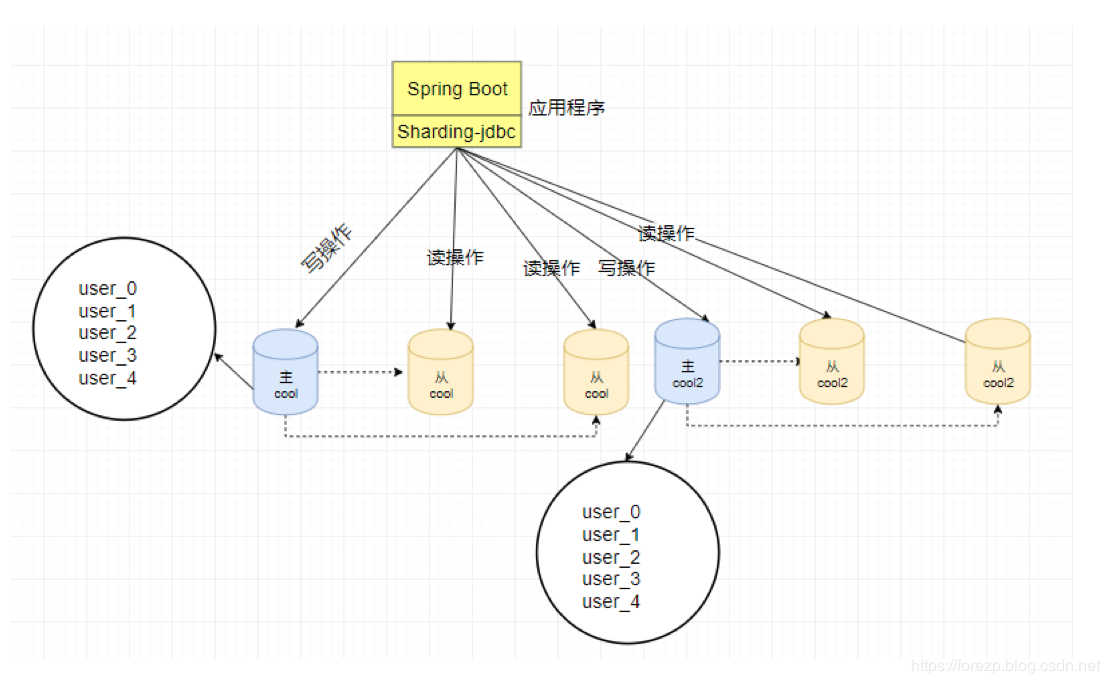
之前我们介绍了Sharding-jdbc的读写分离,这一文,我们实现分表分库。
官方文档地址:https://shardingsphere.apache.org/document/current/cn/overview/

一、首先创建一个一般的Spring boot项目,加入pom
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
<!--mysql-->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<scope>runtime</scope>
</dependency>
<dependency>
<groupId>org.mybatis.spring.boot</groupId>
<artifactId>mybatis-spring-boot-starter</artifactId>
<version>2.1.0</version>
</dependency>
<!--shardingsphere start-->
<!-- for spring boot -->
<dependency>
<groupId>io.shardingsphere</groupId>
<artifactId>sharding-jdbc-spring-boot-starter</artifactId>
<version>3.1.0</version>
</dependency>
<!-- for spring namespace -->
<dependency>
<groupId>io.shardingsphere</groupId>
<artifactId>sharding-jdbc-spring-namespace</artifactId>
<version>3.1.0</version>
</dependency>
<!--shardingsphere end-->
<!--lombok-->
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
</dependency>
二、我们先准备下数据库
我们准备三个库 db01、db02、db03,每个库两个表 user_01 \user_02.
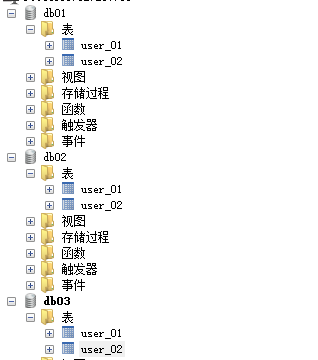
表结构:
CREATE TABLE `user_01` (
`id` BIGINT(20) NOT NULL,
`name` VARCHAR(255) DEFAULT NULL,
`num` INT(11) DEFAULT '0',
PRIMARY KEY (`id`)
) ENGINE=INNODB DEFAULT CHARSET=utf8
三、编写springboot+mybatis的查询代码
mapper:
public interface UserMapper {
@Select({
"select * from user where id=#{id}"
})
User findUserById(@Param("id") Long id);
@Select({
"<script>",
"SELECT * FROM `user` WHERE id in ",
"<foreach item=\"item\" index=\"index\" collection=\"ids\" open=\"(\" separator=\",\" close=\")\">",
" #{item}",
"</foreach>",
"</script>",
})
List<User> findUserList(@Param("ids") List<Long> ids);
}
UserController
@GetMapping("/query")
public User findUserById(@RequestParam("id") Long id) {
return userService.findUserById(id);
}
@PostMapping("/querys")
public List<User> findUserList(@RequestBody List<Long> ids) {
return userService.findUserList(ids);
}
四、编写配置文件
# 数据源 db01,db02,db03
sharding.jdbc.datasource.names=db01,db02,db03
# 第一个数据库
sharding.jdbc.datasource.db01.type=com.zaxxer.hikari.HikariDataSource
sharding.jdbc.datasource.db01.driver-class-name=com.mysql.cj.jdbc.Driver
sharding.jdbc.datasource.db01.jdbc-url=jdbc:mysql://10.10.10.10:3306/db01?useUnicode=true&useJDBCCompliantTimezoneShift=true&useLegacyDatetimeCode=false&serverTimezone=UTC
sharding.jdbc.datasource.db01.username=root
sharding.jdbc.datasource.db01.password=
# 第二个数据库
sharding.jdbc.datasource.db02.type=com.zaxxer.hikari.HikariDataSource
sharding.jdbc.datasource.db02.driver-class-name=com.mysql.cj.jdbc.Driver
sharding.jdbc.datasource.db02.jdbc-url=jdbc:mysql://10.10.10.10:3306/db02?useUnicode=true&useJDBCCompliantTimezoneShift=true&useLegacyDatetimeCode=false&serverTimezone=UTC
sharding.jdbc.datasource.db02.username=root
sharding.jdbc.datasource.db02.password=
# 第三个数据库
sharding.jdbc.datasource.db03.type=com.zaxxer.hikari.HikariDataSource
sharding.jdbc.datasource.db03.driver-class-name=com.mysql.cj.jdbc.Driver
sharding.jdbc.datasource.db03.jdbc-url=jdbc:mysql://10.10.10.10:3306/db03?useUnicode=true&useJDBCCompliantTimezoneShift=true&useLegacyDatetimeCode=false&serverTimezone=UTC
sharding.jdbc.datasource.db03.username=root
sharding.jdbc.datasource.db03.password=
# 水平拆分的数据库(表) 配置分库 + 分表策略 行表达式分片策略
# 分库策略
sharding.jdbc.config.sharding.default-database-strategy.inline.sharding-column=id
sharding.jdbc.config.sharding.default-database-strategy.inline.algorithm-expression=db0$->{(id % 3)+1}
# 分表策略 其中book为逻辑表 分表主要取决于id行
sharding.jdbc.config.sharding.tables.user.actual-data-nodes=db0$->{1..3}.user_0$->{1..2}
sharding.jdbc.config.sharding.tables.user.table-strategy.inline.sharding-column=id
# 分片算法表达式
sharding.jdbc.config.sharding.tables.user.table-strategy.inline.algorithm-expression=user_0$->{(id % 2)+1}
# 主键 UUID 18位数 如果是分布式还要进行一个设置 防止主键重复
#sharding.jdbc.config.sharding.tables.user.key-generator-column-name=id
# 打印执行的数据库以及语句
sharding.jdbc.config.props..sql.show=true
spring.main.allow-bean-definition-overriding=true
#读写分离
sharding.jdbc.datasource.dsmaster =
五、启动项目,我们测试下
1、调用单个查询接口

原始sql:
select * from user where id=?
最终sql
select * from user_02 where id=? ::: [[9]]
2、调用批量查询接口

原始sql:
SELECT * FROM `user` WHERE id in ( ? , ? , ? , ? , ? , ? )
最终sql
: Actual SQL: db01 ::: SELECT * FROM `user_01` WHERE id in ( ? , ? , ? , ? , ? , ? ) ::: [[1, 2, 3, 4, 5, 6]]
2020-04-02 14:30:26.571 INFO 15908 --- [nio-8080-exec-1] ShardingSphere-SQL : Actual SQL: db01 ::: SELECT * FROM `user_02` WHERE id in ( ? , ? , ? , ? , ? , ? ) ::: [[1, 2, 3, 4, 5, 6]]
2020-04-02 14:30:26.571 INFO 15908 --- [nio-8080-exec-1] ShardingSphere-SQL : Actual SQL: db02 ::: SELECT * FROM `user_01` WHERE id in ( ? , ? , ? , ? , ? , ? ) ::: [[1, 2, 3, 4, 5, 6]]
2020-04-02 14:30:26.571 INFO 15908 --- [nio-8080-exec-1] ShardingSphere-SQL : Actual SQL: db02 ::: SELECT * FROM `user_02` WHERE id in ( ? , ? , ? , ? , ? , ? ) ::: [[1, 2, 3, 4, 5, 6]]
2020-04-02 14:30:26.571 INFO 15908 --- [nio-8080-exec-1] ShardingSphere-SQL : Actual SQL: db03 ::: SELECT * FROM `user_01` WHERE id in ( ? , ? , ? , ? , ? , ? ) ::: [[1, 2, 3, 4, 5, 6]]
2020-04-02 14:30:26.571 INFO 15908 --- [nio-8080-exec-1] ShardingSphere-SQL : Actual SQL: db03 ::: SELECT * FROM `user_02` WHERE id in ( ? , ? , ? , ? , ? , ? ) ::: [[1, 2, 3, 4, 5, 6]]